


【Notebook】Finetuning Torchvision Models
15 Oct 2018 | finetuning feature-extractionFinetuning & Feature Extraction
In this tutorial we will take a deeper look at how to finetune and feature extract the torchvision models, all of which have been pretrained on the 1000-class Imagenet dataset. This tutorial will give an indepth look at how to work with several modern CNN architectures, and will build an intuition for finetuning any PyTorch model. Since each model architecture is different, there is no boilerplate finetuning code that will work in all scenarios. Rather, the researcher must look at the existing architecture and make custom adjustments for each model.
import torch
import torch.nn as nn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
print("PyTorch Version: ", torch.__version__)
print("TorchVision Version: ", torchvision.__version__)
PyTorch Version: 0.4.1
TorchVision Version: 0.2.1
# Top level data directory. Here we assume the format of the direcory conforms
# to the ImageFolder structure
data_dir = "./hymenoptera_data"
# Models to choose from [resnet, alexnet, vgg, squeezenet, densenet, inception]
model_name = "squeezenet"
# Number of classes in the dataset
num_classes = 2
# Batch size for training (change depending on how much memory you have)
batch_size = 8
# Numbers of epochs to train for
num_epochs = 15
# Flag for feature extracting. When False, we finetune the whole model,
# when True we only update the reshaped layer params
feature_extract = True
# The train_model function handles the training and validation of a given model.
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25,is_inception=False):
since = time.time()
val_acc_history = []
bese_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-'*10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
# Get model outputs and calculate loss
# Special case for inception because in training it has an auxiliary output. In train
# mode we calculate the loss by summing the final output and the auxiliary output
# but in testing we only consider the final output.
if is_inception and phase == 'train':
# From https://discuss.pytorch.org/t/how-to-optimize-inception-model-with-auxiliary-classifiers/7958
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4 * loss2
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'val':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60,
time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_history
Set Model Parameters’ .requires_grad attribute
This helper function sets the .requires_grad attribute of the parameters in the model to False when we are feature extracting.By default, when we load a pretrained model all of the parameters have .requires_grad=True, which is fine if we are training from scratch or finetuning.
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
Initialize And Reshape The Networks
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# Initialize these variables which will be set in this if statement. Each of these variable is model specific.
model_ft = None
input_size = 0
if model_name == "resnet":
"""Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
"""Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "squeezenet":
"""Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299, 299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
# Initialize the model for this run
model_ft, input_size = initialize_model(model_name, num_classes, feature_extract, use_pretrained=True)
# Print the models we just instantiate
print(model_ft)
SqueezeNet(
(features): Sequential(
(0): Conv2d(3, 96, kernel_size=(7, 7), stride=(2, 2))
(1): ReLU(inplace)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(3): Fire(
(squeeze): Conv2d(96, 16, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(16, 64, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(16, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(4): Fire(
(squeeze): Conv2d(128, 16, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(16, 64, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(16, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(5): Fire(
(squeeze): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(6): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(7): Fire(
(squeeze): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(8): Fire(
(squeeze): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(48, 192, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(48, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(9): Fire(
(squeeze): Conv2d(384, 48, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(48, 192, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(48, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(10): Fire(
(squeeze): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(11): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(12): Fire(
(squeeze): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
)
(classifier): Sequential(
(0): Dropout(p=0.5)
(1): Conv2d(512, 2, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace)
(3): AvgPool2d(kernel_size=13, stride=1, padding=0)
)
)
/home/sven/anaconda3/lib/python3.6/site-packages/torchvision-0.2.1-py3.6.egg/torchvision/models/squeezenet.py:94: UserWarning: nn.init.kaiming_uniform is now deprecated in favor of nn.init.kaiming_uniform_.
/home/sven/anaconda3/lib/python3.6/site-packages/torchvision-0.2.1-py3.6.egg/torchvision/models/squeezenet.py:92: UserWarning: nn.init.normal is now deprecated in favor of nn.init.normal_.
Load Data
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]), # transforms.Normalize([mean, std]) : mean and standard deviation
'val': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
print("Initializing Datasets and Dataloaders...")
# Create training and validation datasets
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'val']}
# Create training and validatioin dataloaders
dataloaders_dict = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=batch_size, shuffle=True, num_workers=4) for x in ['train', 'val']}
# Detect if we have a GPU avaliable
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
Initializing Datasets and Dataloaders...
Create The Optimizer
from torch import optim
# Send the model to GPU
model_ft = model_ft.to(device)
# Gather the parameters to be optimized/updated in this run. If we are
# finetuning we will be updating all parameters. However, if we are
# doing feature extract method, we will only update the parameters
# that we have just initialized, i.e. the parameters with requires_grad
# is True.
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update =[]
for name, param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t", name)
else:
for name, param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t", name)
# Observe that all parameter are being optimized
optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
Params to learn:
classifier.1.weight
classifier.1.bias
Run Training And Validation Step
# Setup the loss fxn
criterion = nn.CrossEntropyLoss()
# Train and evaluate
model_ft, hist = train_model(model_ft, dataloaders_dict, criterion, optimizer_ft,
num_epochs=num_epochs, is_inception=(model_name=="inception"))
Epoch 0/14
----------
train Loss: 0.5321 Acc: 0.7377
val Loss: 0.3811 Acc: 0.8889
Epoch 1/14
----------
train Loss: 0.3144 Acc: 0.8770
val Loss: 0.3804 Acc: 0.8889
Epoch 2/14
----------
train Loss: 0.2763 Acc: 0.8975
val Loss: 0.3630 Acc: 0.9085
Epoch 3/14
----------
train Loss: 0.1918 Acc: 0.9098
val Loss: 0.3561 Acc: 0.9150
Epoch 4/14
----------
train Loss: 0.1564 Acc: 0.9139
val Loss: 0.4090 Acc: 0.9150
Epoch 5/14
----------
train Loss: 0.1707 Acc: 0.9221
val Loss: 0.3403 Acc: 0.9150
Epoch 6/14
----------
train Loss: 0.1613 Acc: 0.9180
val Loss: 0.4437 Acc: 0.9085
Epoch 7/14
----------
train Loss: 0.1945 Acc: 0.9057
val Loss: 0.3642 Acc: 0.9020
Epoch 8/14
----------
train Loss: 0.1207 Acc: 0.9549
val Loss: 0.4013 Acc: 0.9216
Epoch 9/14
----------
train Loss: 0.1604 Acc: 0.9385
val Loss: 0.3707 Acc: 0.9150
Epoch 10/14
----------
train Loss: 0.1296 Acc: 0.9426
val Loss: 0.4175 Acc: 0.9346
Epoch 11/14
----------
train Loss: 0.0926 Acc: 0.9754
val Loss: 0.4020 Acc: 0.9346
Epoch 12/14
----------
train Loss: 0.1266 Acc: 0.9590
val Loss: 0.3714 Acc: 0.9150
Epoch 13/14
----------
train Loss: 0.0924 Acc: 0.9672
val Loss: 0.5276 Acc: 0.8954
Epoch 14/14
----------
train Loss: 0.0995 Acc: 0.9549
val Loss: 0.4544 Acc: 0.9216
Training complete in 0m 27s
Best val Acc: 0.934641
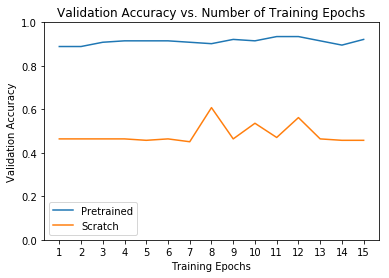
Comparison With Model Trained From Scratch
# Initialize the non-pretrained version of the model used for this run
scratch_model, _ = initialize_model(model_name, num_classes, feature_extract=False,
use_pretrained=False)
scratch_model = scratch_model.to(device)
scratch_optimizer = optim.SGD(scratch_model.parameters(), lr=0.001, momentum=0.9)
scratch_criterion = nn.CrossEntropyLoss()
_, scratch_hist = train_model(scratch_model, dataloaders_dict, scratch_criterion,
scratch_optimizer, num_epochs=num_epochs, is_inception=(model_name=="inception"))
# Plot the training curves of validation accuracy vs. number
# of training epochs for the transfer learning method and
# the model trained from stractch
ohist = []
shist = []
ohist = [h.cpu().numpy() for h in hist]
shist = [h.cpu().numpy() for h in scratch_hist]
plt.title("Validation Accuracy vs. Number of Training Epochs")
plt.xlabel("Training Epochs")
plt.ylabel("Validation Accuracy")
plt.plot(range(1, num_epochs+1), ohist, label="Pretrained")
plt.plot(range(1, num_epochs+1), shist, label="Scratch")
plt.ylim((0, 1.))
plt.xticks(np.arange(1, num_epochs+1, 1.0))
plt.legend()
plt.show()
Epoch 0/14
----------
/home/sven/anaconda3/lib/python3.6/site-packages/torchvision-0.2.1-py3.6.egg/torchvision/models/squeezenet.py:94: UserWarning: nn.init.kaiming_uniform is now deprecated in favor of nn.init.kaiming_uniform_.
/home/sven/anaconda3/lib/python3.6/site-packages/torchvision-0.2.1-py3.6.egg/torchvision/models/squeezenet.py:92: UserWarning: nn.init.normal is now deprecated in favor of nn.init.normal_.
train Loss: 0.6985 Acc: 0.5164
val Loss: 0.6931 Acc: 0.4641
Epoch 1/14
----------
train Loss: 0.6929 Acc: 0.5000
val Loss: 0.6931 Acc: 0.4641
Epoch 2/14
----------
train Loss: 0.6931 Acc: 0.5123
val Loss: 0.6931 Acc: 0.4641
Epoch 3/14
----------
train Loss: 0.6932 Acc: 0.4959
val Loss: 0.6931 Acc: 0.4641
Epoch 4/14
----------
train Loss: 0.6932 Acc: 0.4959
val Loss: 0.6931 Acc: 0.4575
Epoch 5/14
----------
train Loss: 0.6935 Acc: 0.5000
val Loss: 0.6931 Acc: 0.4641
Epoch 6/14
----------
train Loss: 0.6925 Acc: 0.4918
val Loss: 0.6931 Acc: 0.4510
Epoch 7/14
----------
train Loss: 0.6905 Acc: 0.4959
val Loss: 0.6920 Acc: 0.6078
Epoch 8/14
----------
train Loss: 0.6914 Acc: 0.4959
val Loss: 0.6931 Acc: 0.4641
Epoch 9/14
----------
train Loss: 0.6912 Acc: 0.5000
val Loss: 0.6918 Acc: 0.5359
Epoch 10/14
----------
train Loss: 0.6877 Acc: 0.5000
val Loss: 0.6931 Acc: 0.4706
Epoch 11/14
----------
train Loss: 0.6849 Acc: 0.5369
val Loss: 0.6659 Acc: 0.5621
Epoch 12/14
----------
train Loss: 0.6743 Acc: 0.4918
val Loss: 0.6931 Acc: 0.4641
Epoch 13/14
----------
train Loss: 0.6931 Acc: 0.5205
val Loss: 0.6931 Acc: 0.4575
Epoch 14/14
----------
train Loss: 0.6932 Acc: 0.4754
val Loss: 0.6931 Acc: 0.4575
Training complete in 0m 40s
Best val Acc: 0.607843
Comments